The value of IP and Domain information
Starting with the end in mind, make the data you have
consumable (and thus actionable), make sense of the data, drive risk decisions,
and share data with trusted partners and shift from routine monitoring to
internal threat intelligence. Start with what you can easily work with like IP
addresses and domains.
Some debate is raging within enclaves of the internet about
the value and accuracy of the APT1 report. The criticism is in the tacit link between the victims and
the numerous sources from a single region of the world, Shanghai China. The APT1 report shared the indicators
of compromise allowing myself and others to compare indicators, signatures etc.
and evaluate the conclusions.
I set out to evaluate and compare file names, hashes, IP
addresses, Domain and all the other atomic indicators from the report against
data I had collected. The overlap
confirmed quite a bit of what I knew prior. How many orgs could go and compare
notes at that level? Not enough.
Anytime a new report is issued with unmasked indicators,
each of us should evaluate the findings.
Sharing and tracking starts with internally sourced threat intelligence
and I would argue that every organization needs the capability, starting with a
simple tracking system. Any atomic
indicator such as hash, IP address, domain, filename, has a half-life of
sorts. As the effectiveness
decreases, it is less likely that you will continue to see in any specific
remote edge of the internet. If
you mined the APT1 report for indicators, most are useless by now.
The net effect of the APT1 report is higher salaries of
these with TI on resumes, and driving business to Mandiant. It made a bunch of security vendors
shift positions and consider how to capitalize on threats. How does one capitalize on any large
list of IPs and domains as found in the APT1 report? If the thinking is to toss it all into a SIEM you might as
well stop reading here.
Threats are associated with IP addresses and domains, but
focusing on IP and Domains alone is pointless because the threat will move and
you have a stale list, ultimately wasting time on false positives. At what point does an IP address stop
being a threat? The domains, IP
addresses, and AS numbers are part of threat intelligence. In a simple example, any point of
concentration of IP or domains tells you that nearby IPs and domains are worthy
of examination during the fleeting time the space is being used.
Why internal threat intelligence?
Internal threat intelligence was initially leveraged by
government and the defense industrial base, at least the smarter ones. Then, it
was the telecoms and large internet service providers and now energy and
financial sectors are making a play for top talent to consume internal TI. How
far does it go? Can we
‘rent’ the skills from TI brokers or commission specialized reports?
Anton Chuvakin in a recent blog explored the difficulties
and objectives of internally sourced threat intelligence, it is worth the
read.
http://blogs.gartner.com/anton-chuvakin/2014/03/20/on-internally-sourced-threat-intelligence My short take is that Internal threat
intelligence evaluates the same information sourced from incidents as anyone
doing monitoring. Internal Threat Intelligence takes a depth and breadth
analytical approach with the available information. Internal Threat
Intelligence is the split between detection and response providing threat suppression.
Internal Threat Intelligence is the hedge against the
immediate threat landscape and what is over the horizon. In my personal view, threat
intelligence is not grounded in large sets of IP and Domains with poor
reputations but having context, history, and in the narrative of objectives and
actors. One cannot reach that
stratum without a solid foundation to collect and analyze the local
information, compare against rational and trusted resources, postulate and test
hypothesis and eventually point fingers.
The APT1 report was a confirmation of findings, not a revelation.
I think internal threat intelligence will be a required part
of monitoring. All analyst should
seek to track IP and addresses locally. It is not enough to consume external
indicators alone. It is not enough to purchase a set of sensors, plugging in
data looking for matches.
Monitoring won’t go away but it will become more automated, becoming
easier to match events, provide entity specific information, and use large data
sources to evaluate relationships, measure impact and finally, drive the
incident response.
Linking events, actions and incident through to actors will
continue to be in demand with the cost being reduced by emerging platforms that
synthesize internal information and rational findings from the outside
world. Fusion is the by-product of
the most useful and reliable sources measured to bring value in understanding
threats. TI is predictive in nature
and about the only way divest from a Maginot line (popular commentary made by
the RSAC ‘C’ level speaking collective, yet useful in my thinking as well).
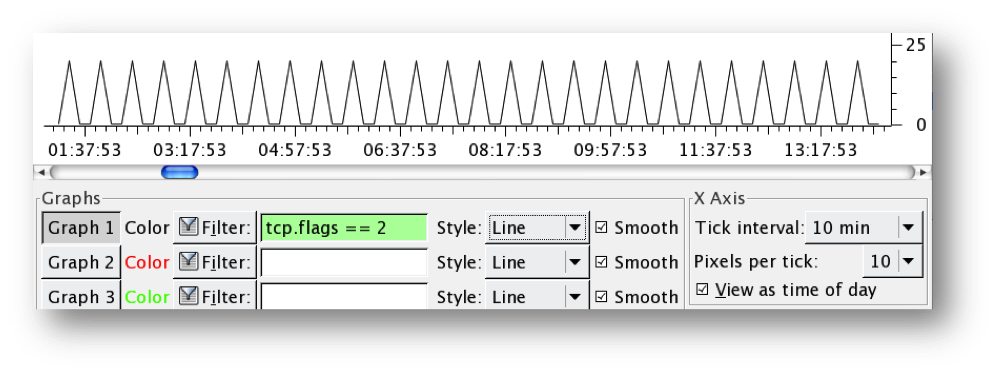
Passive DNS
I was introduced to passive DNS as a useful analytical tool
a few years ago when someone I once worked with wrote his own variant using
Python and MySQL. What I learned
is the value of tracking just the right amount of information exceeds the value
of tracking all of the information, and using only public DNS information is
futile. The instant utility of
passive DNS for each enterprise seemed evident to me, however this particular
implementation suffered performance issues that became unbearable in just a few
days. Ultimately, it was scrapped after a month or so.
Before I go further, exact matching IP and Domains is nearly
futile and won’t compare to the value of computed and some behavioral
indicators. Understanding why a
stream between host contains 'system32' with a file
write operation of a ‘rar’ file or batch file has a better chance a detecting
pivot for example. If you intend
to track, choose to do it well. The
idea that you could shop and explore known IP or domain address and get a sense
of when the query was first made, how many and what neighboring domains and
addresses were doing is valuable.
Passive DNS is not new, but I don’t think the general
utility to analyst is well understood.
In my view, SecurityOnion should have the capability.
Tracking means a composite of domains
and IP address within your own environment, instantly searchable.
At higher levels, a potential threat
detection system with room to innovate.
Florian
Weimer introduced passive DNS many years ago (paper
http://www.enyo.de/fw/software/dnslogger/first2005-paper.pdf)
and it is well worth the read.
Plenty of services exist in the commercial space for analyzing your DNS
records for potential threats like OpenDNS’s Umbrella and Damballa.
With the services, you get the value of
the analytics at scale, and each has invested in exploring and improving
detection, with the most virulent malicious actions being noticed and
suppressed with speed.
However, the targeted attacks may not have enough
concurrency to get noticed, that is to say a single domain that does not fall
into set characteristic using SVM, or not newly registered, falls below a
noticeable threshold used in large-scale detection. This is where your own passive DNS tracking comes in handy
and could be complimentary to any network security monitoring service, network
monitoring, and especially local sourced threat intelligence.
Passive DNS version 2
Like my former coworker, I wrote scripts to collect and
analyze DNS information but made some design decisions that require a bit of
explaining up front. Before
getting into the specific, it is important to know that passive DNS or pDNS is
not logging. That is to say, each
record is not being appended to a file.
However, each DNS query and response is being tracked. If a domain and IP has never been seen
before, a new record is created, if already in database, the count is
incremented and only date field is overwritten, reducing the amount of data
stored.
MySQL was replaced with Redis for speed improvements. In my
home spun version, the same fields parsed from any DNS query and response are
present including keys for threatening IP addresses and Domains. Time and time again, analyst visit the
web and dig and lookup names, use reputation systems to enumerate all the bad
in the world. Useful and important
to validate against the outside world and get a sense of risk, but a step
closer to home is far more useful first.
The worst part about this sort of query is the lack of accounting. Analyst will most likely make the same
query time and again or several analyst may make the same query and only
tracking confirmed threats. Lost
is the idea of possible threats and sites that are trusted.
In my own variation of pDNS (I call it pDNS2), The basic
properties allow analyst to find the most useful information quickly:
·
Seek all domains that end, start, or contain a
particular word
·
Seek specific TTL or very low TTLs
·
List all the known threatening IP or domains
·
Contrast threat information against other IPs
and domains
·
Export the threatening IP and Domains
·
Return a count of specific subdomains for a given
domain example
·
Counts the top ‘hits' for domains in order
·
Query a range of IP addresses
·
Find local resolved IP addresses for parked
domains like 127.0.0.1
·
Locate all the domains that point to a single IP
·
Locate all the IP associated with any domain
·
Tag a Domain or IP address with a notion of
trust, threat, or interest
·
Search by Date
·
Count how many new domains show up each day
·
Returns Euclidian distance from a queried IP to
a tagged threat
·
Find the most unanswered queries by count
For the most part the code is useful as a means to explore
and track, initiating a home grown threat intelligence effort. You can find the
code on github here:
https://github.com/bez0r/pDNS2
(specifically the query tool ‘pdns2_query_api.py’
was released in support of this post)
Advanced pDNS2
With the basics of passive DNS covered, a separate
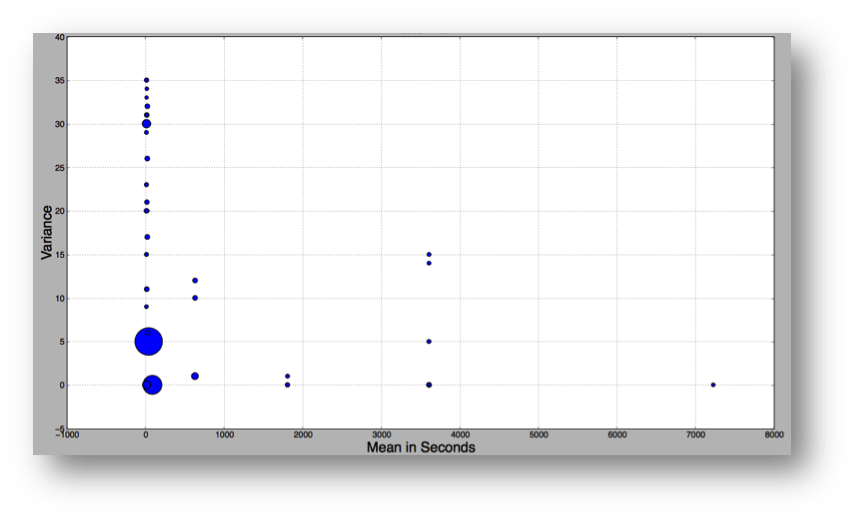
analytical script was developed to explore specific information and calculate a
concept of risk.
New domains are
checked against a corpus of known good and bad using simple Bayesian ML and
another does a random forest walk (concept was from a talk in 2013 by EndGame
Systems).
In the Bayesian example
below, a check of unknowns was pulled from old ‘conficker’ domains to get a
sense of how well it works (source:
http://blogs.technet.com/b/msrc/archive/2009/02/12/conficker-domain-information.aspx)
Queries can assist an analyst in finding out the most likely
domains a site is trying to squat or mimic. Any local domain suspected as a potential threat can be
submitted to any of the top reputation sites with returned results used to help
score the potential threat.
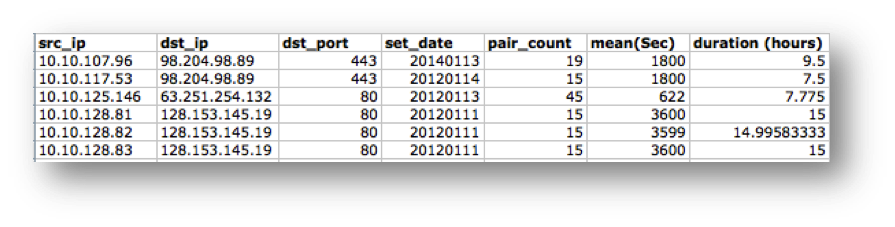
Additional static sources were included to support domain
queries from project Sonar (
https://community.rapid7.com/community/infosec/sonar/blog/2013/09/26/welcome-to-project-sonar),
so a query returned information about
the reverse IPv4, SSL certs, and the usual data around regions and
registration.
Scoring threat by
known properties such as how new a domain was registered, low TTL, and resource
record types like TXT that can be used as a command and control channel can
lead to analyst starting with the most probable threats.
One little script goes out and scrapes
sites for IP/Dom and another script import/export for STIX files.
Over time the pDNS2 scripts were tied to each sensor so a
simple right click would provide context. The pDNS2 tools started out as a way
to quickly makes sense of the IP and Domain space, and later, a support system
for local threat intelligence and a driver of Analytics. After all this, I
converted the basic scripts into glorious functions and tossed the entire tool
set into an iPython Notebook where analyst can save and share notebooks.
Conclusions
You won’t find any ‘ground truth’ data above or research,
but you should be thinking about elevating monitoring and use the information
already at your finger tips to capitalize on ‘internal threat
intelligence’. I did not attend
RSAC this year but the undercurrent of talks is in a wide range of hub and
spoke information sharing collectives as a service is intriguing. You can share in the trading of useful
information or you can buy a service that will do it on your behalf. Most organization want to consume
indicators, yet lack the ability to organize the right information. Especially if the information is not
directly involved in incidents is too sensitive to share. This is where Mandiant comes in for the
win, sharing IOCs while offering a veil of protection for some victims.
I contend the pDNS2 is trivial to initiate and to get into a
workflow but it does not stand alone. Other interesting tools like ‘malcom’ (
https://github.com/jipegit/malcom)
has overlap and does a far better job at presentation and incorporates several
feeds against internal ‘live’ sensors.
This post is making an argument that internal threat
intelligence is worth the effort, that tracking data such as IP and Domains is
not futile and that now is the time for analyst and monitors to effectively
become internal TI.